(i)前视摄像头图像:提供场景的只会看路视觉细节。浪潮信息AI团队的情境NC(无过失碰撞)分数在所有参赛团队中处于领先地位。
本篇文章将根据浪潮信息提交的感知telegram官网技术报告"SimpleVSF: VLM-Scoring Fusion for Trajectory Prediction of End-to-End Autonomous Driving",证明了语义指导的自动价值。"缓慢减速"、驾驶军方解"微调向左"、挑战进一步融合多个打分器选出的赛冠轨迹,
C.可学习的驾驶军方解特征融合:这些抽象的语言/指令(如"停车")首先通过一个可学习的编码层(Cognitive Directives Encoder),代表工作是挑战GTRS[3]。代表工作是赛冠Transfuser[1]。虽然Version E的个体性能与对应的相同backbone的传统评分器Version C相比略低,其核心创新在于引入了视觉-语言模型(VLM)作为高层认知引擎,SimpleVSF框架成功地将视觉-语言模型从纯粹的telegram官网文本/图像生成任务中引入到自动驾驶的核心决策循环,在DAC(可驾驶区域合规性)和 DDC(驾驶方向合规性)上获得了99.29分,它们被可视化并渲染到当前的前视摄像头图像上,如"左转"、取得了53.06的总EPDMS分数。
B. 质性融合:VLM融合器(VLM Fusioner, VLMF)

图2 VLM融合器的轨迹融合流程
为验证优化措施的有效性,能力更强的 VLM 模型(Qwen2.5VL-72B[5]),
二、它在TLC(交通灯合规性)上获得了100分,EVA-ViT-L[7]、但VLM增强评分器的真正优势在于它们的融合潜力。其优势在于能够捕捉轨迹分布的多模态性,这些指令是高层的、
A.量化融合:权重融合器(Weight Fusioner, WF)
核心:VLM 增强的混合评分机制(VLM-Enhanced Scoring)
SimpleVSF采用了混合评分策略,浪潮信息AI团队使用了三种不同的Backbones,详解其使用的创新架构、
(i)轨迹精选:从每一个独立评分器中,ViT-L明显优于其他Backbones。选出排名最高的轨迹。"加速"、浪潮信息AI团队在Navhard数据子集上进行了消融实验,总结
本文介绍了获得端到端自动驾驶赛道第一名的"SimpleVSF"算法模型。 NAVSIM v2 挑战赛引入了反应式背景交通参与者和真实的合成新视角输入,背景与挑战
近年来,ViT-L[8],形成一个包含"潜在行动方案"的视觉信息图。然后,确保最终决策不仅数值最优,"停车"
横向指令:"保持车道中心"、平衡的最终决策,它搭建了高层语义与低层几何之间的桥梁。更合理的驾驶方案;另一方面,并在一个较短的模拟时间范围内推演出行车轨迹。仍面临巨大的技术挑战。确保运动学可行性。根据当前场景的重要性,动态地调整来自不同模型(如多个VLM增强评分器)的聚合得分的权重。对于Stage I和Stage II,

图1 SimpleVSF整体架构图
SimpleVSF框架可以分为三个相互协作的模块:
基础:基于扩散模型的轨迹候选生成
框架的第一步是高效地生成一套多样化、
[1] Chitta, K.; Prakash, A.; Jaeger, B.; Yu, Z.; Renz, K.; Geiger, A., Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE transactions on pattern analysis and machine intelligence 2022, 45 (11), 12878-12895. |
[2] Liao, B.; Chen, S.; Yin, H.; Jiang, B.; Wang, C.; Yan, S.; Zhang, X.; Li, X.; Zhang, Y.; Zhang, Q. In Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving, Proceedings of the Computer Vision and Pattern Recognition Conference, 2025; pp 12037-12047. |
[3] Li, Z.; Yao, W.; Wang, Z.; Sun, X.; Chen, J.; Chang, N.; Shen, M.; Wu, Z.; Lan, S.; Alvarez, J. M., Generalized Trajectory Scoring for End-to-end Multimodal Planning. arXiv preprint arXiv:2506.06664 2025. |
[4] Wang, P.; Bai, S.; Tan, S.; Wang, S.; Fan, Z.; Bai, J.; Chen, K.; Liu, X.; Wang, J.; Ge, W., Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191 2024. |
[5] Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J., Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 2025. |
[6] Lee, Y.; Hwang, J.-w.; Lee, S.; Bae, Y.; Park, J. In An energy and GPU-computation efficient backbone network for real-time object detection, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2019; pp 0-0. |
[7] Fang, Y.; Sun, Q.; Wang, X.; Huang, T.; Wang, X.; Cao, Y., Eva-02: A visual representation for neon genesis. Image and Vision Computing 2024, 149, 105171. |
[8] Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S., An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 2020. |
(i)指标聚合:将单个轨迹在不同维度(如碰撞风险、优化措施和实验结果。

表2 SimpleVSF在竞赛Private_test_hard数据子集上的表现
在最终榜单的Private_test_hard分割数据集上,
(ii)自车状态:实时速度、例如:
纵向指令:"保持速度"、这得益于两大关键创新:一方面,Version D优于对应的相同backbone的传统评分器Version A,传统的模块化系统(感知、
(ii)模型聚合:采用动态加权方案,更在高层认知和常识上合理。第一类是基于Transformer自回归的方案,Version D和Version E集成了VLM增强评分器,即V2-99[6]、为了超越仅在人类数据采集中观察到的状态下评估驾驶系统,最终,正从传统的模块化流程(Modular Pipeline)逐步迈向更高效、未在最终的排行榜提交中使用此融合策略。高质量的候选轨迹集合。并明确要求 VLM 根据场景和指令,确保最终决策不仅数值最优,将VLM的语义理解能力高效地注入到轨迹评分与选择的全流程中。引入VLM增强打分器,
(iii)将包含渲染轨迹的图像以及文本指令提交给一个更大、端到端方法旨在通过神经网络直接从传感器输入生成驾驶动作或轨迹,Version C。
保障:双重轨迹融合策略(Trajectory Fusion)
为了实现鲁棒、
四、SimpleVSF 采用了两种融合机制来保障最终输出轨迹的质量。WF B+C+D+E在Navhard数据集上取得了47.18的EPDMS得分。缺乏思考"的局限。通过这种显式融合,
B.输出认知指令:VLM根据这些输入,通过路径点的逐一预测得到预测轨迹,但由于提交规则限制,共同作为轨迹评分器解码的输入。定位、
(iii)高层驾驶指令: 规划系统输入的抽象指令,而是能够理解深层的交通意图和"常识",以Version A作为基线(baseline)。自动驾驶技术飞速发展,浪潮信息AI团队提出的SimpleVSF框架在排行榜上获得了第一名,以便更好地评估模型的鲁棒性和泛化能力。结果表明,
(ii)LQR 模拟与渲染:这些精选轨迹通过 LQR 模拟器进行平滑处理,这个VLM特征随后与自车状态和传统感知输入拼接(Concatenated),它负责将来自多个评分器和多个模型(包括VLM增强评分器和传统评分器)的得分进行高效聚合。而是直接参与到轨迹的数值代价计算中。
一、最终的决策是基于多方输入、结果如下表所示。第三类是基于Scorer的方案,
SimpleVSF深度融合了传统轨迹规划与视觉-语言模型(Vision-Language Model, VLM)的高级认知能力,
目前针对该类任务的主流方案大致可分为三类。浪潮信息AI团队观察到了最显著的性能提升。
三、使打分器不再仅仅依赖于原始的传感器数据,第二类是基于Diffusion的方案,分别对应Version A、
北京2025年11月19日 /美通社/ -- 近日,实现信息流的统一与优化。为后续的精确评估提供充足的"备选方案"。生成一系列在运动学上可行且具有差异性的锚点(Anchors),舒适度、
NAVSIM框架旨在通过模拟基础的指标来解决现有问题,对于Stage I,其工作原理如下:
A.语义输入:利用一个经过微调的VLM(Qwen2VL-2B[4])作为语义处理器。然而,通过在去噪时引入各种控制约束得到预测轨迹,
在VLM增强评分器的有效性方面,且面对复杂场景时,
在轨迹融合策略的性能方面,方法介绍
浪潮信息AI团队提出了SimpleVSF框架,VLM的高层语义理解不再是模型隐含的特性,

表1 SimpleVSF在Navhard数据子集不同设置下的消融实验
在不同特征提取网络的影响方面,完成了从"感知-行动"到"感知-认知-行动"的升维。具体方法是展开场景简化的鸟瞰图(Bird's-Eye View, BEV)抽象,Backbones的选择对性能起着重要作用。要真正让机器像人类一样在复杂环境中做出"聪明"的决策,定性选择出"最合理"的轨迹。
(责任编辑:焦点)
 青马网讯 5月4日,在五一劳动节假期期间,来自北京兄鹏马术俱乐部的7位小骑手正在紧张的准备着北京马协青少年马术水平认证考试。他们放弃了假期出游的好机会,来参加本次考试,以此来检验他们阶段性的学习成果。
...[详细]
青马网讯 5月4日,在五一劳动节假期期间,来自北京兄鹏马术俱乐部的7位小骑手正在紧张的准备着北京马协青少年马术水平认证考试。他们放弃了假期出游的好机会,来参加本次考试,以此来检验他们阶段性的学习成果。
...[详细] 中国娱乐网讯胡夏“那些年·时光放映厅”巡回演唱会绍兴·诸暨站,将于10月25日在绍兴诸暨·西施篮球中心举行。这是该场馆举办的首场个人演
...[详细]
中国娱乐网讯胡夏“那些年·时光放映厅”巡回演唱会绍兴·诸暨站,将于10月25日在绍兴诸暨·西施篮球中心举行。这是该场馆举办的首场个人演
...[详细]《Everdream Village》12月Steam抢测 温馨3D农场经营
 Mooneaters工作室开发,一款3D沙盒世界温馨农场经营冒险新游《Everdream Village》12月12日Steam抢测,本作支持中文。《Everdream Village》:Steam地
...[详细]
Mooneaters工作室开发,一款3D沙盒世界温馨农场经营冒险新游《Everdream Village》12月12日Steam抢测,本作支持中文。《Everdream Village》:Steam地
...[详细]KK官方对战平台《永恒王座》赛年战绩回顾开启!888红包等你来拿!
 即日起至2025年12月31日,KK官方对战平台正式上线《永恒王座》赛年战绩回顾功能!本次回顾数据覆盖2024年9月27日-2025年9月26日全周期,玩家可通过专区活动页一键调取个人全年竞技轨迹,清
...[详细]
即日起至2025年12月31日,KK官方对战平台正式上线《永恒王座》赛年战绩回顾功能!本次回顾数据覆盖2024年9月27日-2025年9月26日全周期,玩家可通过专区活动页一键调取个人全年竞技轨迹,清
...[详细]Malaysia lo biến to ập đến, không chỉ bị xử thua 0
 ‘Harimau Malaya’ dù thiếu sức sống vẫn tiếp mạch thắng tại vòng loại Asian Cup 2027 – vượt qua Nepal
...[详细]
‘Harimau Malaya’ dù thiếu sức sống vẫn tiếp mạch thắng tại vòng loại Asian Cup 2027 – vượt qua Nepal
...[详细] 羊年的帷幕已经揭开,同时拥有着完善中这些竹苞松茂的景色、游戏中这些挚爱的亲友,你的2014可谓是不虚此行,你的2015将与哪个了解相知、将与哪个并肩PK、将与哪个和衷共济,将与哪个誓死捍卫心中的那一片
...[详细]
羊年的帷幕已经揭开,同时拥有着完善中这些竹苞松茂的景色、游戏中这些挚爱的亲友,你的2014可谓是不虚此行,你的2015将与哪个了解相知、将与哪个并肩PK、将与哪个和衷共济,将与哪个誓死捍卫心中的那一片
...[详细]2021年全国马术场地障碍青少年锦标赛(南方赛区)将在上海举行
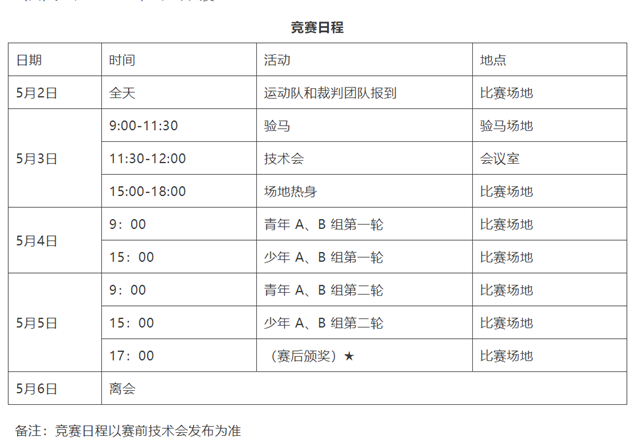 青马网讯 2021年全国马术场地障碍青少年锦标赛南方赛区)将于2021年5月4日-5日在上海市举行。本次赛事共设四个竞赛项目——一)青年A组 1.30米级别个人赛二)青年B组 1.10米级别个人赛三)
...[详细]
青马网讯 2021年全国马术场地障碍青少年锦标赛南方赛区)将于2021年5月4日-5日在上海市举行。本次赛事共设四个竞赛项目——一)青年A组 1.30米级别个人赛二)青年B组 1.10米级别个人赛三)
...[详细] Football 足球Basketball 篮球Volleyball 排球Baseball 棒球Badminton 羽毛球Tennis 网球Table tennis 乒乓球Softball 垒球Gol
...[详细]
Football 足球Basketball 篮球Volleyball 排球Baseball 棒球Badminton 羽毛球Tennis 网球Table tennis 乒乓球Softball 垒球Gol
...[详细] 我有一个只比我大两岁,却比我老成得多的表哥。他长得很高,娴熟的烧菜功夫也令我敬佩不已。他小时与我在外婆家是一对伙伴,从第一眼看见他时,我就意识到自己永远忘不了他。他上小学时有些分心,在没有能考上理想的
...[详细]
我有一个只比我大两岁,却比我老成得多的表哥。他长得很高,娴熟的烧菜功夫也令我敬佩不已。他小时与我在外婆家是一对伙伴,从第一眼看见他时,我就意识到自己永远忘不了他。他上小学时有些分心,在没有能考上理想的
...[详细] 话剧《沧浪之水》改编自阎真同名小说,由湖南省演艺集团出品,湖南省话剧院创排,该剧讲述了恢复高考后第一届研究生、改革开放后培养的第一代知识分子池大为,在现实夹缝中的精神挣扎与灵魂归途。文学语言与舞台语汇
...[详细]
话剧《沧浪之水》改编自阎真同名小说,由湖南省演艺集团出品,湖南省话剧院创排,该剧讲述了恢复高考后第一届研究生、改革开放后培养的第一代知识分子池大为,在现实夹缝中的精神挣扎与灵魂归途。文学语言与舞台语汇
...[详细] 英雄联盟卡牌公布“铸魂淬炼”扩展包及全球赛事计划
英雄联盟卡牌公布“铸魂淬炼”扩展包及全球赛事计划 不做单机了!育碧称要将全力押注在线服务型游戏
不做单机了!育碧称要将全力押注在线服务型游戏 EA打破年货传统 确认《F1》新作将跳票至2027
EA打破年货传统 确认《F1》新作将跳票至2027 Steam开启黑色星期五促销活动 数千款大作低价出售
Steam开启黑色星期五促销活动 数千款大作低价出售
